library(grid)
## 1. Function to annotate decile interval for each test statistic t
annotate_decile_range <- function(decile){
q = decile
## First annotate if each t is <= decile q
decile_range <- if_else(df$t <= quantile(df$t, q), paste("leq", q), paste("g", q))
while(q > 0.1){
## Then annotate if each t is between decile q-1 and q
decile_range[which(df$t > quantile(df$t, q-0.1) &
df$t <= quantile(df$t, q))] <- paste("g", q-0.1, ", leq", q)
q = q - 0.1
}
decile_range[which(df$t <= quantile(df$t, 0.1))] <- "leq 0.1"
df$decile_range <- decile_range
return(df)
}
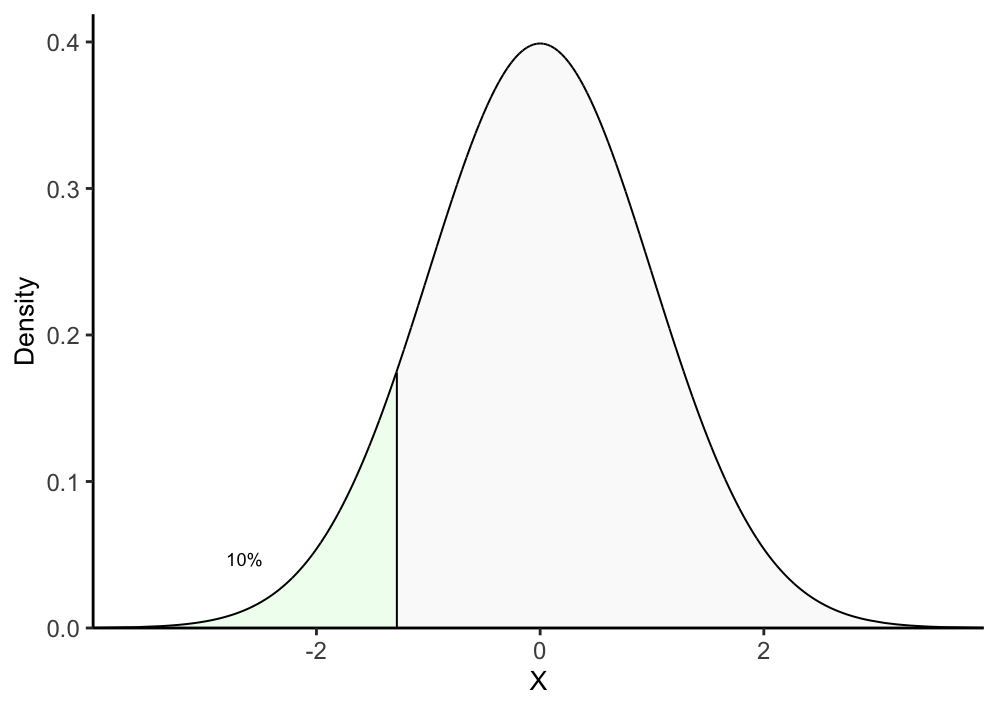
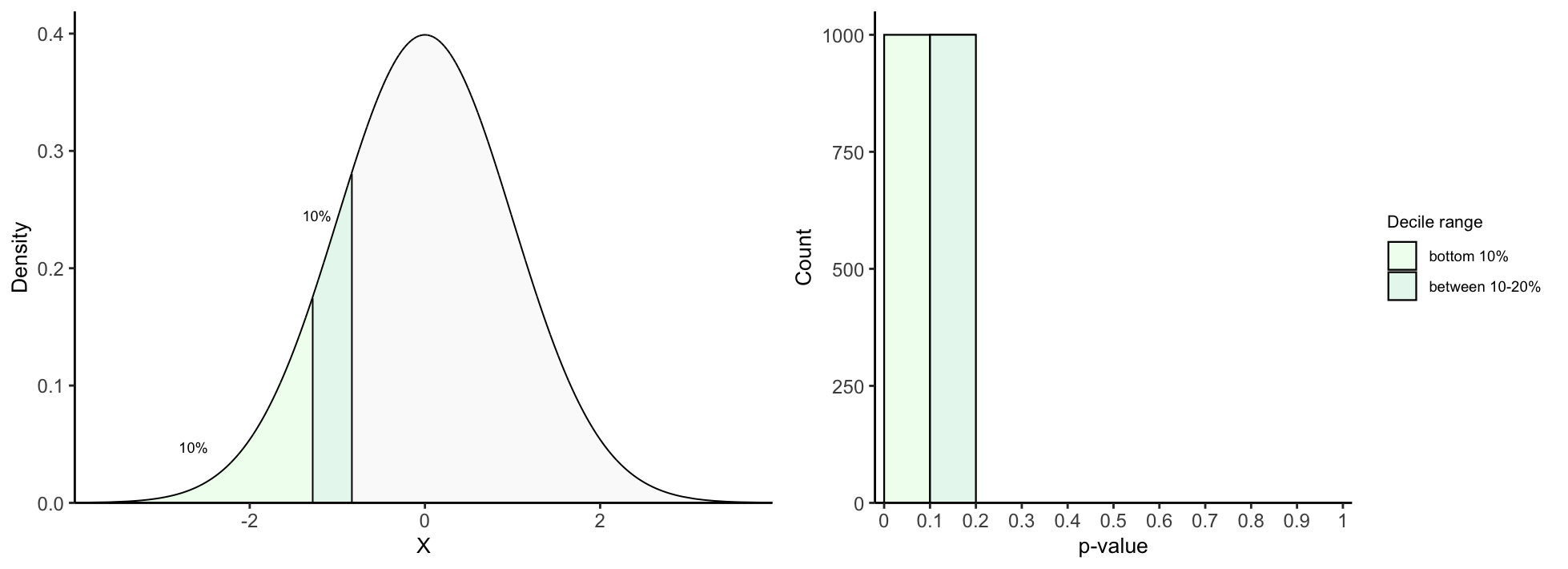
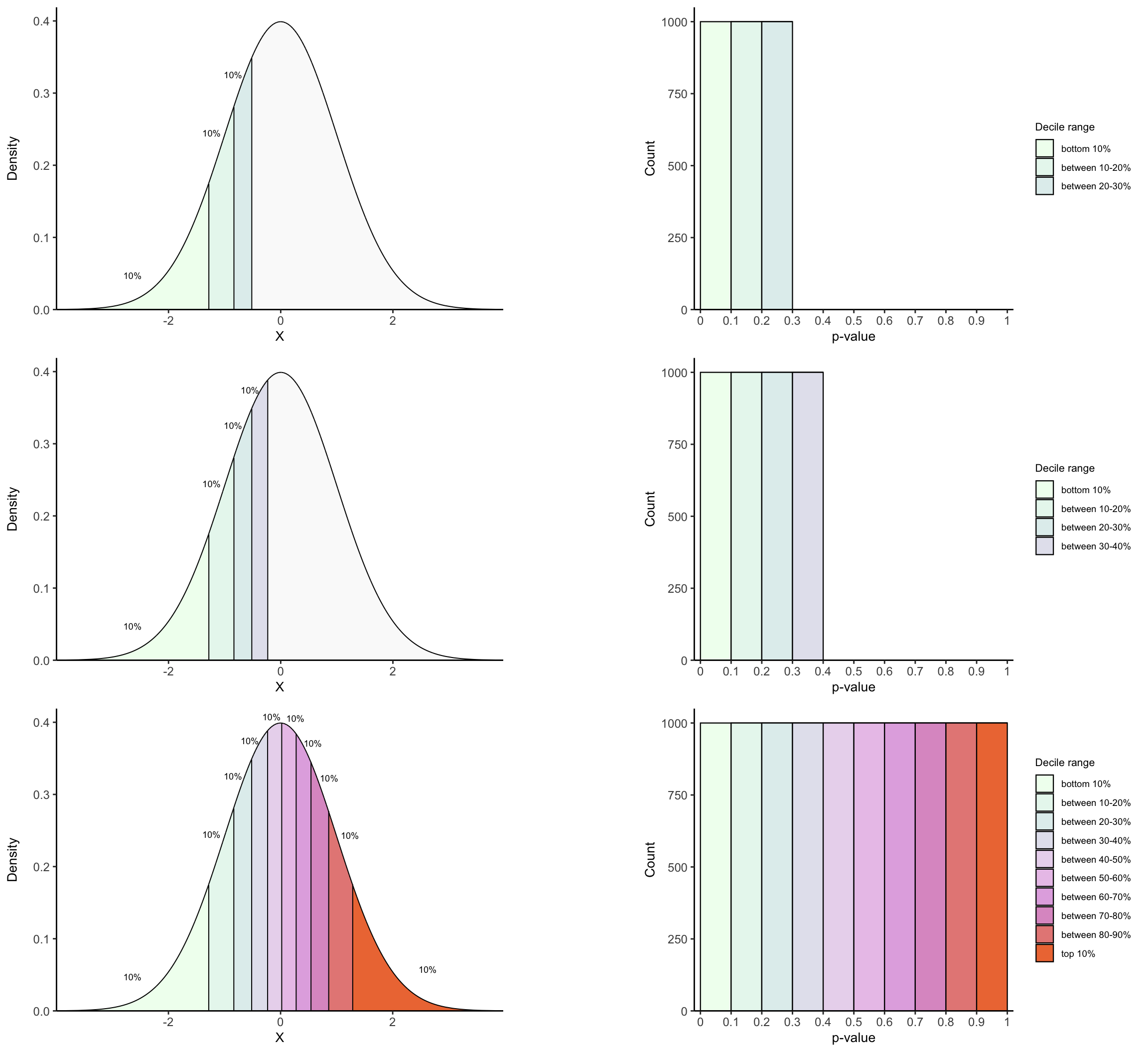
## 2. Function to color decile intervals in T density up to decile q
plot_density_decile <- function(decile){
df <- annotate_decile_range(decile)
## Colors and alphas for decile ranges
range_colors = c(colorRampPalette(c("honeydew1", "azure2", "thistle2","plum",
"sienna2"))(10), "gray90")
range_alphas = c(rep(1, 10), 0.2)
names(range_colors) <- names(range_alphas) <- c("leq 0.1",
paste("g", seq(from = 0.1, to = 0.9, by = 0.1), ",", "leq",
seq(from = 0.1, to = 0.9, by = 0.1) + 0.1),
paste("g", decile))
vlines <- vector()
for(q in seq(from = 0.1, to = decile, by = 0.1)){
## For vertical lines in each decile
x = quantile(df$t, q)
xend = quantile(df$t, q)
y = 0
yend = df[which.min(abs(df$t - x)), "y"]
## For annotating "10%" above each decile interval
prior_x = quantile(df$t, q-0.1)
prior_yend = df[which.min(abs(df$t - prior_x)), "y"]
middle_x = prior_x + (x - prior_x)/2
middle_y = prior_yend + (yend - prior_yend)/2
if(q == 0.1){
lab_x_pos = middle_x
lab_y_pos = middle_y - 0.04
}
else if(q == 1){
lab_x_pos = middle_x
lab_y_pos = middle_y - 0.03
}
else if(q == 0.5){
lab_x_pos = middle_x - 0.05
lab_y_pos = middle_y + 0.014
}
else if(q == 0.6){
lab_x_pos = middle_x + 0.12
lab_y_pos = middle_y + 0.014
}
else{
lab_x_pos = middle_x + (sign(x)*0.17)
diff_y = abs((yend - prior_yend)/2)
lab_y_pos = middle_y + (diff_y*0.33)
}
vlines <- rbind(vlines, c(q, x, xend, y, yend, lab_x_pos, lab_y_pos))
}
vlines <- as.data.frame(vlines)
colnames(vlines) <- c("decile", "x", "xend", "y", "yend", "lab_x_pos", "lab_y_pos")
plot <- ggplot(data = df, aes(x = t, ymin = 0, ymax = y,
fill = decile_range,
alpha = decile_range)) +
geom_ribbon(color = "black", linewidth = 0.35) +
theme_classic() +
scale_fill_manual(values = range_colors) +
scale_alpha_manual(values = range_alphas) +
labs(x = "T",
y = "Density") +
geom_segment(data = vlines, inherit.aes = F,
aes(x = x + 0.005,
xend = xend + 0.005,
y = y, yend = yend),
linewidth = 0.35, show.legend = F) +
geom_text(data = vlines, inherit.aes = F,
aes(x = lab_x_pos, y = lab_y_pos), label ="10%",
size = 2.4, show.legend = F) +
guides(fill = "none", alpha = "none") +
coord_cartesian(ylim = c(0, max(df$y)+0.02), expand = F) +
theme(axis.text = element_text(size = 9),
legend.text = element_text(size = 7),
legend.title = element_text(size =8),
legend.key.height = unit(0.5, "cm"),
legend.key.width = unit(0.5, "cm"),
axis.title.x = element_text(size = 10),
axis.title.y = element_text(size = 10))
## To add labels for 1st and 2nd deciles
if(decile == 0.1){
plot <- plot + geom_text(aes(x = vlines[1,"x"], y = 0.015,
label = expression(t["10%"])),
inherit.aes = F, parse = T, size = 3.3)
}
else if(decile == 0.2){
plot <- plot + geom_text(aes(x = vlines[1,"x"]-0.07, y = 0.015,
label = expression(t["10%"])),
inherit.aes = F, parse = T, size = 3.4) +
geom_text(aes(x = vlines[2,"x"]+0.07, y = 0.015,
label = expression(t["20%"])),
inherit.aes = F, parse = T, size = 3.4)
}
return(plot)
}
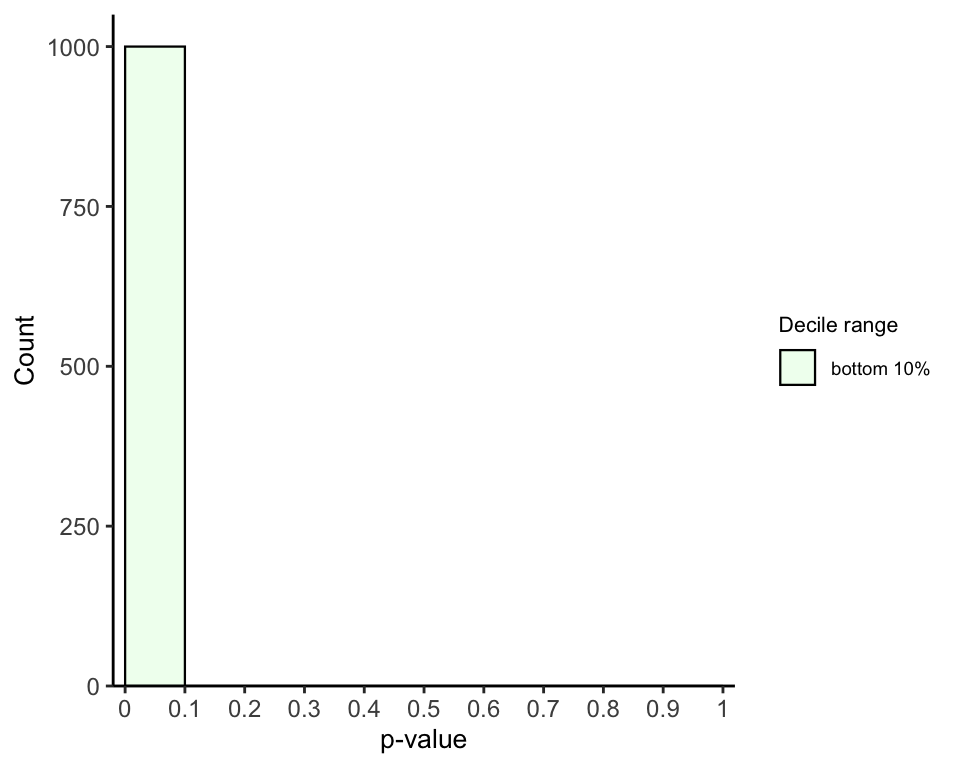
## 3. Function to plot pval histogram up to decile q
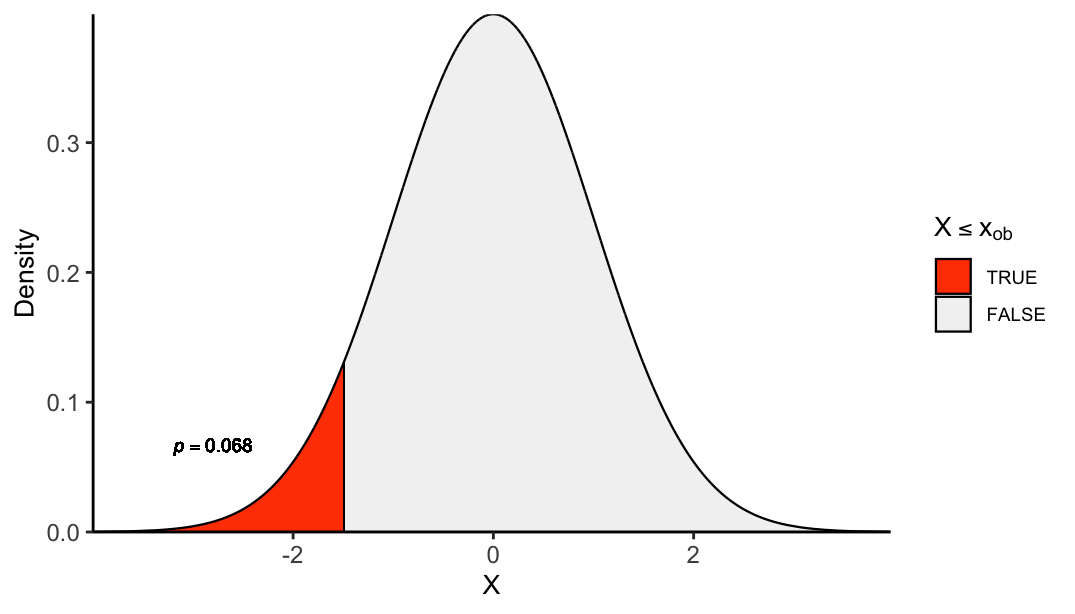
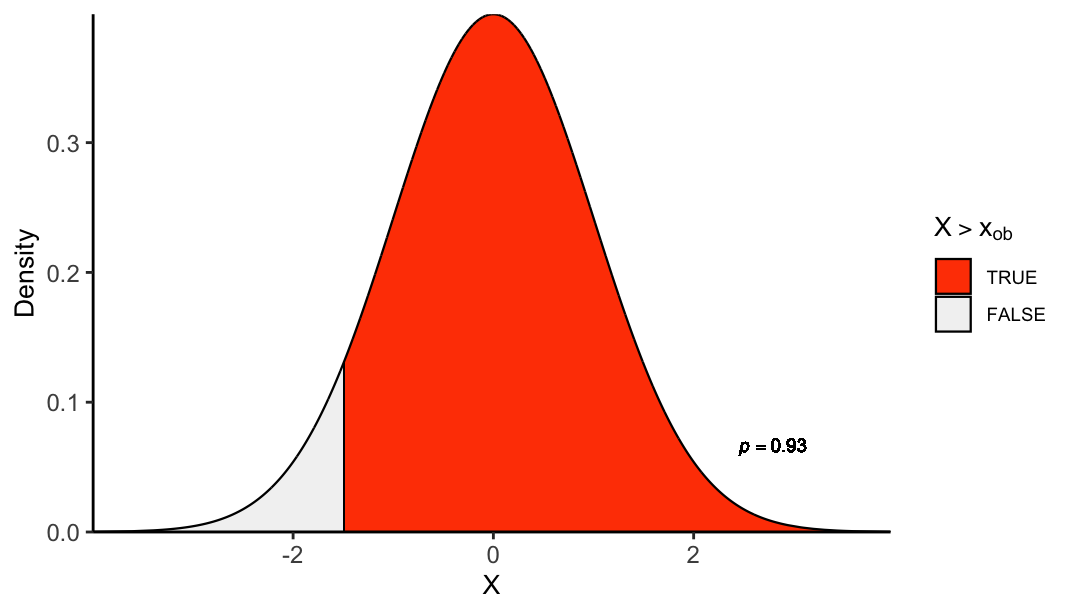
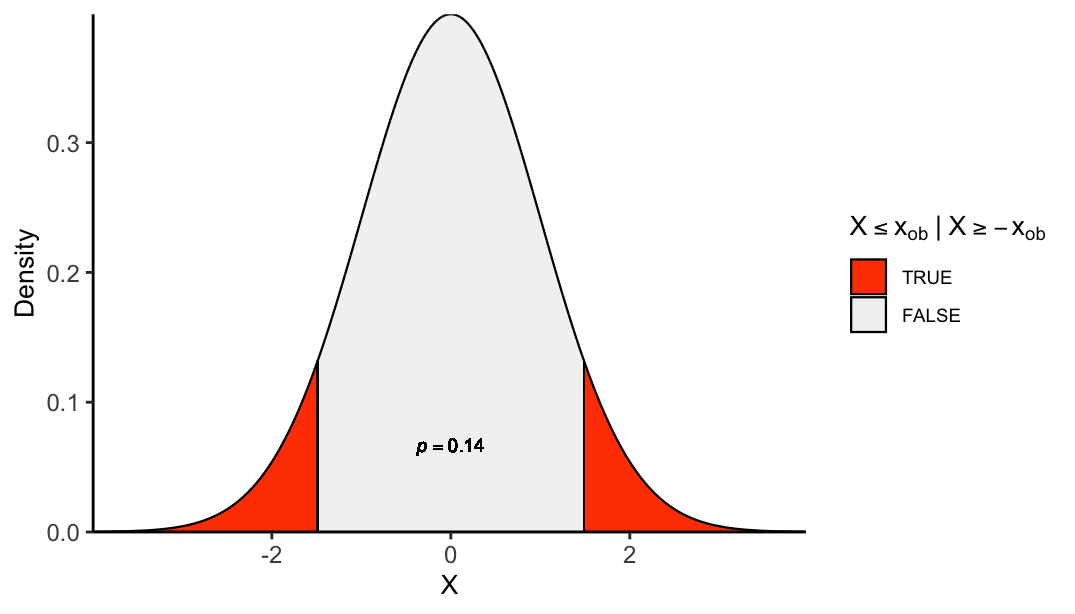
plot_pval_hist <- function(decile, tail){
if(tail == "left"){
tail_pvals <- "left_tailed_pval"
} else if(tail == "right"){
tail_pvals <- "right_tailed_pval"
} else{
tail_pvals <- "two_tailed_pval"
}
## Colors and alphas for decile ranges
range_colors = colorRampPalette(c("honeydew1", "azure2","thistle2","plum",
"sienna2"))(10)
names(range_colors) <- c("leq 0.1",
paste("g", seq(from = 0.1, to = 0.9, by = 0.1), ",", "leq",
seq(from = 0.1, to = 0.9, by = 0.1) + 0.1))
decile_ranges_labs <- c("bottom 10%", "between 10-20%", "between 20-30%", "between 30-40%",
"between 40-50%", "between 50-60%", "between 60-70%",
"between 70-80%","between 80-90%", "top 10%")
names(decile_ranges_labs) <- names(range_colors)
df <- annotate_decile_range(decile)
decile_ranges <- setdiff(unique(df$decile_range), paste("g", decile))
data = subset(df, decile_range %in% decile_ranges)
data$decile_range <- factor(data$decile_range, levels = names(decile_ranges_labs))
if(tail == "both"){
data$decile_range <- factor(data$decile_range, levels = rev(names(decile_ranges_labs)))
}
## Histogram
ggplot(data, aes(x = get(tail_pvals), fill = decile_range)) +
geom_histogram(color="black", bins = 10, binwidth = 0.3, linewidth = 0.4,
breaks = seq(from = 0, to = 1, by = 0.1)) +
theme_classic() +
scale_fill_manual(values = range_colors, labels = decile_ranges_labs[decile_ranges]) +
coord_cartesian(xlim = c(-0.02, 1.02), ylim = c(0, 1050), expand = F) +
scale_x_continuous(breaks = seq(from = 0, to = 1, by = 0.1),
labels = seq(from = 0, to = 1, by = 0.1)) +
labs(x = "p-value", y = "Count", fill = "Decile interval") +
theme(axis.text = element_text(size = 9),
legend.text = element_text(size = 7),
legend.title = element_text(size =8),
legend.key.height = unit(0.5, "cm"),
legend.key.width = unit(0.5, "cm"),
axis.title.x = element_text(size = 10),
axis.title.y = element_text(size = 10))
}